Designing Workloads for Kinetic Resilience
Early in my career, I worked for a construction equipment company in Peoria, Illinois. Every week, I drove to a facility in Mossville, Illinois to rotate backup tapes. The first time I made that drive, I expected a data center. What I found was a factory floor, rows of diesel engines painted bright yellow, lined up in neat formation. The “computer room” sat underground, accessed through a walkway cut into the middle of the factory. Next to it was a safe room, built for the people working above.
I grew up in the South of India known for its dry and tropical and predicatable climate and I had never experienced a tornado. My only reference to a Tornado was the movie Twister. But Mossville sits in central Illinois, where tornadoes are not a hypothetical risk. They are a recurring one. The factory’s designers understood this. They placed the computer room underground, beside the shelter, because they recognized that protecting digital infrastructure meant accounting for physical destruction.
That underground computer room was our disaster recovery facility. It was not elegant. But it reflected a design principle that remains relevant today. Infrastructure must survive the loss of the building above it.
Decades later in 2026, the threat landscape has changed. Data centers no longer face only tornadoes, floods, or earthquakes. Recent geopolitical events have exposed a different category of risk i.e. deliberate, targeted, physical attacks on digital infrastructure. Drone strikes have disabled power stations in Ukraine. Undersea cables have been severed in the Baltic Sea. Governments are reassessing the physical vulnerability of facilities they once considered secure.
The question is no longer whether a data center can withstand an equipment failure or a natural disaster. The question is whether your workloads can survive the intentional destruction of the facility that hosts them.
This post examines what it means to design for that scenario.
The Problem, Infrastructure Built for Accidents, Not Attacks
Data center design has been driven by a single objective for decades. Maintain availability in the face of failure. The industry has built mature approaches to achieve this through redundant power, backup cooling, multiple availability zones, automated failover, and cross-region replication. These practices work. But they share a common assumption that the facility itself continues to exist.
Kinetic threats break that assumption. A drone strike does not cause a recoverable hardware fault. A missile does not trigger a graceful failover. The destruction of a facility can be permanent, immediate, and total.
Since 2022, military strikes have destroyed power infrastructure that data centers depended on. Undersea cables have been severed. Attacks on maritime chokepoints have threatened cable routes carrying an estimated 17% of global internet traffic. And in 2026, drone strikes directly damaged cloud data center facilities for the first time, marking the moment kinetic threats moved from adjacent infrastructure to the cloud infrastructure itself. The World Economic Forum responded by calling for digital infrastructure to be treated as critical infrastructure on par with power grids and water systems (source).
The Limits of Traditional Availability Models
Traditional high availability works through layered redundancy. Redundant power, cooling, and network paths at the facility level. Load balancing and automated instance replacement at the application level. Multiple availability zones at the regional level. A 2025 Uptime Institute report found that 55% of data center outages were power-related, and the majority were resolved within hours through existing redundancy. The model works because it addresses the failure modes that occur with the highest frequency.
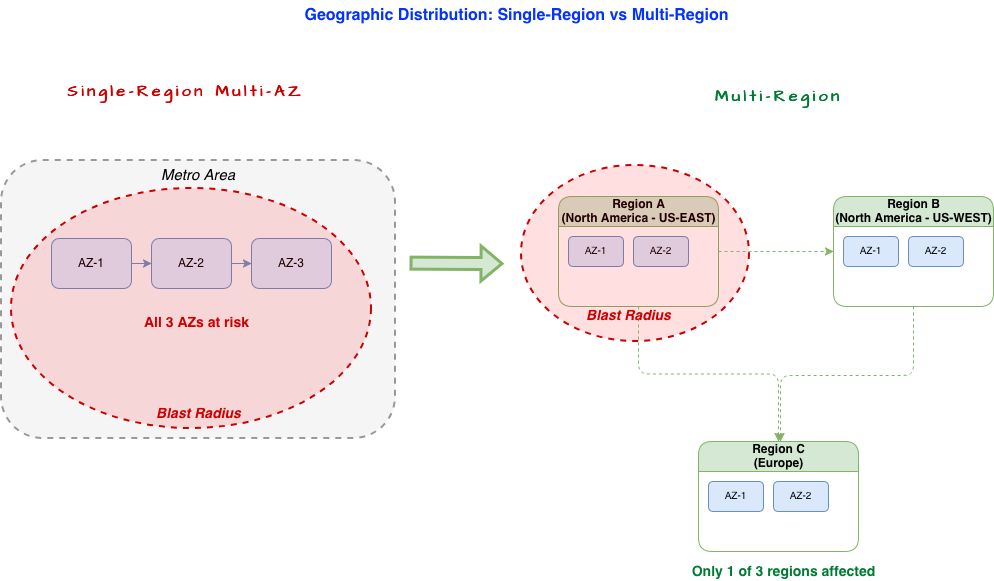
The gap appears when you examine the assumptions underneath. Availability zones within a single region are typically located within the same metropolitan area, within 100 kilometers of each other. They share the same power grid, the same internet exchange points, and the same political jurisdiction. A localized natural disaster can affect one zone while sparing others. A coordinated physical attack does not respect availability zone boundaries. If three zones sit within the same city and that city becomes a conflict zone, all three are at risk simultaneously.
Multi-region architectures reduce this exposure, but a majority of organizations default to a primary-secondary model where one availability zone in a region handles writes and the other serves as a warm standby. In a kinetic scenario, the loss of the primary region means the loss of all data not yet replicated, and a failover process that has never been tested under real conditions.
The result is a gap between what organizations believe their architecture can survive and what it actually can. Closing that gap is what kinetic resilience is about.
From Availability to Kinetic Resilience
Traditional resilience asks, “What happens when a component fails?” Kinetic resilience asks a different question. “What happens when the facility no longer exists?”
Component failure is temporary and recoverable. Facility destruction can be permanent and total. The recovery playbook for the first scenario does not apply to the second. There is no hardware to replace. There is no facility to restore into.
Kinetic resilience accounts for three scenarios that traditional models treat as edge cases. The permanent loss of a facility. The prolonged inaccessibility of an entire region due to conflict, government shutdown, or sustained infrastructure damage. And the disruption of external dependencies that facilities rely on to function, particularly power grids, fuel supply chains, and network interconnects.
The objective is not to prevent damage. The objective is to ensure that the destruction of any single facility, or even an entire region, does not cause a corresponding destruction of the services running on it. Resilience becomes a property of the workload, not the building. The workload survives because it was designed to exist independently of any single location.
Architectural Strategies for Kinetic Resilience
If resilience is a property of the workload rather than the facility, then the architecture must reflect that. Four strategies form the foundation.
Geographic Distribution Beyond Availability Zones
Multi-region architectures are the strongest foundation for kinetic resilience. By distributing workloads across geographically separated regions, they isolate failures and reduce the blast radius of any single event. For workloads that face kinetic risk, multi-region is not optional. It is the starting point.
The next step is ensuring that the regions themselves are distributed across boundaries that matter. Regions that do not share the same power grid, the same government jurisdiction, or the same geopolitical risk profile provide stronger isolation than regions clustered within a single country. A workload running in three regions across two continents is harder to disable through physical attack than one running in three availability zones within the same metropolitan corridor.
The trade-off is latency. Synchronous replication across regions is impractical for latency-sensitive applications. Workloads that require strong consistency need conflict resolution mechanisms, eventual consistency models, or partitioned write domains that allow each region to operate independently while reconciling state asynchronously.
The other trade-off is regulatory. Data sovereignty laws require that certain categories of data remain within national or regional boundaries. Kinetic resilience does not require ignoring these constraints. It requires designing around them by separating the data layer from the compute and control layers. Regulated data stays within the required jurisdiction. The compute layer distributes across broader boundaries so the system continues to operate even if one jurisdiction’s facilities are compromised.
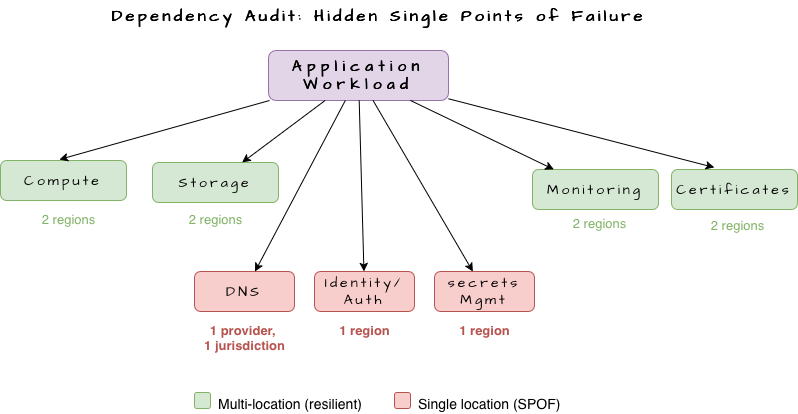
Elimination of Single Points of Failure
No individual facility can be essential to the operation of the whole system. Single points of failure hide in unexpected places. A “multi-region” deployment where all DNS is managed from one provider in one jurisdiction. A primary write database that has never been promoted under load. A secrets manager or identity provider that runs in one location.
Eliminating these requires a systematic audit of every dependency in the stack. Each dependency must answer one question. If the facility hosting this component is destroyed in the next ten minutes, does the system continue to function? The implementation is active-active deployments where each site handles full production traffic, multi-writer databases or partitioned ownership models, and stateless service components wherever possible. A facility loss should result in reduced capacity, not systemic failure.
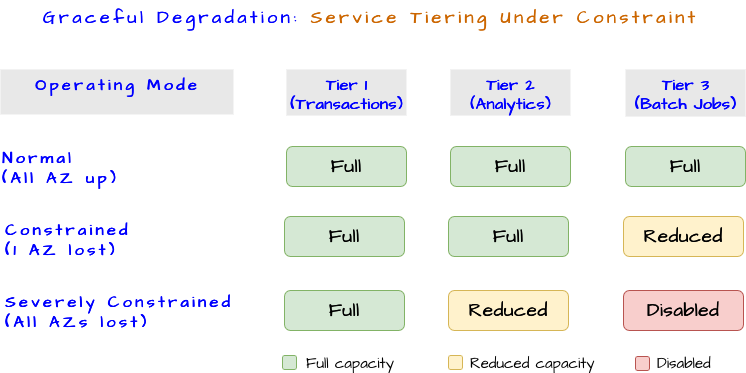
Graceful Degradation
A system that loses 30% of its infrastructure is not down. It is constrained. Graceful degradation means the system sheds non-essential functions to preserve essential ones. A financial platform disables analytics while maintaining transaction processing. A communications platform reduces video quality while maintaining voice and text.
This requires explicit decisions about service priority, made before the crisis, not during it. Every service needs a tier assignment. Load shedding strategies, circuit breakers, and feature flags become operational necessities. The data layer must also handle partial failure by serving requests with potentially stale data rather than returning errors, which means designing for eventual consistency from the start.
Independence from External Infrastructure
A data center that survives a military strike but loses power three hours later because the regional grid was also targeted has not achieved kinetic resilience. Physical disruptions affect the surrounding infrastructure, including power generation, fuel delivery, cooling water supply, and network connectivity.
Facilities in high-risk environments need independent power generation, cooling systems that operate without municipal water and power, and diverse network paths with multiple upstream providers and satellite backup links. Full independence is not feasible indefinitely. But extending the operational window from hours to days can mean the difference between a managed failover and a catastrophic loss.

Physical Hardening and Countermeasures
Architecture alone does not address the full threat surface. Physical hardening reduces the likelihood and severity of facility loss. Data center security has historically focused on the perimeter, with fences, bollards, and biometric access control protecting against ground-level entry. The roof has received far less attention, and the drone era has exposed that gap. FPV drones attack from above, cost a few hundred dollars, and are increasingly autonomous. Countermeasures proven in active conflict zones, including anti-drone netting, slat armor over rooftop equipment, electronic countermeasures, and visual obscuration, can be adapted for data center rooftops (source).
Structural reinforcement such as blast-resistant construction and subterranean placement further reduce vulnerability. The Mossville computer room from the opening of this post is an early example, placing infrastructure underground eliminates the roof as an attack surface entirely.
Physical hardening buys time, but it does not eliminate risk. It does not address regional disruptions that affect multiple facilities simultaneously, and it creates a false sense of security if the workload architecture underneath still has single points of failure. Hardening protects the facility. Architecture protects the workload. The correct approach is to pair both, harden the facility to reduce risk and architect the workload to absorb loss.
Testing and Validation
An architecture designed for kinetic resilience is only as credible as the scenarios it has been tested against. Conventional DR testing simulates the loss of a component, verifies failover, and records a pass. It does not validate that the system can survive the permanent destruction of a facility.
Kinetic resilience testing requires three additional scenarios, incorporated into the DR program organizations already operate.
Permanent facility loss. Remove a facility from the system entirely. Offline the DNS system supporting the region, withdraw its network routes, mark its data stores as permanently unavailable. The question is whether the system reaches a stable operating state and sustains production load for 48 to 72 hours without it.
Extended regional outage. Simulate a full region offline condition. A 30-minute failover test does not reveal the challenges that emerge at hour 12 or hour 48, such as certificate expirations, token refreshes, cache warming, and the human fatigue of operating in degraded mode.
Cascading dependency failure. This is very difficult scenario to test but nevertheless important. Simulate a facility loss while simultaneously disabling the network paths and monitoring system that would normally alert the on-call team. This surfaces the hidden dependencies and circular alerting paths that architecture reviews miss.
These scenarios belong inside existing DR programs, not alongside them. The investment is in expanding the scope of what gets tested, not in building a new process. And the tests must include the human response. The on-call engineer will be operating under stress, with incomplete information, without access to tools hosted in the destroyed facility. If the team cannot stabilize the system under those conditions, the architecture is not kinetically resilient regardless of what the design documents say.
Conclusion
Not every system needs kinetic resilience. Traditional high availability with regular backups remains appropriate for the majority of applications. This level of investment is justified when the consequences of failure extend beyond the organization itself, in systems like critical infrastructure, financial platforms, government services, and large-scale cloud providers where the impact of a facility loss reaches millions of downstream users.
The Shift in Perspective
The underground computer room in Mossville was built by engineers who understood that the building above it could be destroyed by a tornado. They did not try to make the building tornado-proof. They placed the infrastructure where the tornado could not reach it.
That same principle applies today, at a different scale and against a different threat. Traditional availability practices remain necessary, but they are no longer sufficient for systems that face deliberate physical threats. Kinetic resilience builds on that foundation by shifting the unit of resilience from the facility to the workload, from the building to the system.
Harden the facility to reduce risk. Architect the workload to absorb loss. Test under realistic conditions. And design every system to answer one question. If this building is gone tomorrow, does the service continue?