Part-2: Who Said Yes? Designing User Consent for AI Agents
In the previous post, Alice had a token with exactly the right scopes, and reporting-agent exchanged it for a narrower delegated token before calling downstream services. The whole flow assumed that first token already existed and already carried the right scopes.
This post rewinds to the step before that. How did Alice actually authorize reporting-agent to act for her? And what changes when she adds a second agent, coding-agent, that needs a completely different set of permissions? If consent is wrong here, every downstream token carries the mistake with it.
Why OAuth Consent Wasn’t Designed for Agents
The OAuth 2.0 authorization code flow was designed for a specific scenario: a human sitting at a browser, reviewing a consent screen for a single application, at one moment in time. “ExampleApp wants to read your reports. Allow or deny?”
Agents break three of those assumptions.
Agents can be long-lived. Alice approves reporting-agent once and it runs for months, often without her watching.
Agents can accumulate capabilities. Coding-agent might start out reading code, then later need to open pull requests, then later need to trigger deployments. Each of those is a different scope.
Agents come in populations. Alice doesn’t use one agent. She uses several, each with different purposes, different risk profiles, and different permission needs. The standard consent screen gives her no way to tell reporting-agent from coding-agent from the dozen other agents her team has rolled out.
Fixing this doesn’t require a new protocol. It requires using OAuth more deliberately.
Register Each Agent as Its Own Client
The first fix is the most important: reporting-agent and coding-agent each get their own OAuth client registration. Not a single shared “agent platform” client that every agent authenticates through.
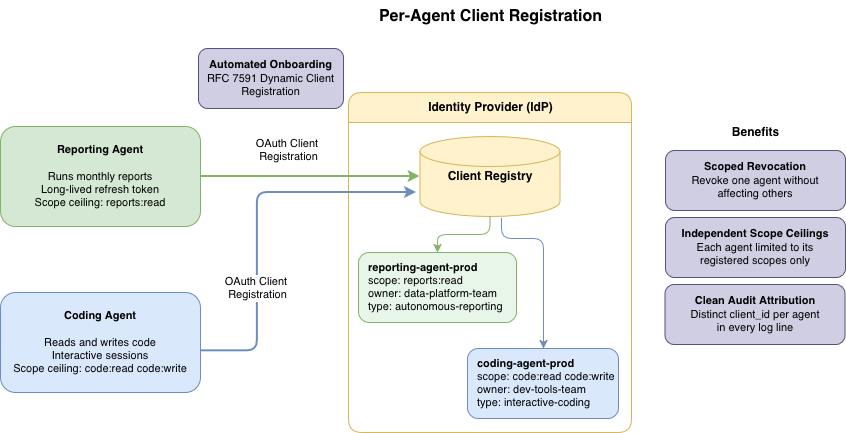
This matters for four reasons.
Onboarding is automated. RFC 7591 Dynamic Client Registration (DCR) lets an agent platform register new clients programmatically when a new agent is deployed. You attach metadata (owner, agent type, declared capabilities, lifecycle state) and treat the client registry as your source of truth for what agents exist and what they are allowed to ask for.
Revocation is scoped. If coding-agent is compromised, you revoke its client registration and every token tied to it. Reporting-agent keeps working. Alice doesn’t get logged out.
Scope ceilings are independent. Reporting-agent’s client is registered with a maximum scope set of reports:read. Coding-agent’s client has code:read code:write. Neither can ever request a scope it wasn’t registered for, regardless of what Alice approves at runtime.
Audit attribution is clean. Every log line carries the specific client ID of the agent that made the call, not a shared identifier that spreads attribution across the whole fleet.
A registered agent client looks roughly like this:
{
"client_id": "reporting-agent-prod",
"client_name": "Reporting Agent",
"grant_types": ["authorization_code", "refresh_token"],
"scope": "reports:read",
"agent_metadata": {
"owner": "data-platform-team",
"agent_type": "autonomous-reporting",
"capability_version": "2.3.0"
}
}
The agent_metadata block is a custom extension. IdPs like Entra ID, Okta, and Cognito let you attach arbitrary metadata to client registrations, and it becomes useful later for policy decisions and incident response.
The Consent Grant: What Alice Actually Approves
With per-agent clients in place, each agent runs its own authorization code flow. Alice sees a distinct consent screen for each one, and grants a distinct set of scopes.

For reporting-agent, the authorization request looks like this:
GET /authorize
?response_type=code
&client_id=reporting-agent-prod
&redirect_uri=https://agents.example.com/callback
&scope=reports:read
&state=xyz123
Alice sees “Reporting Agent wants to read your reports” and approves. She gets a refresh token tied to reporting-agent’s client ID with a scope ceiling of reports:read.
For coding-agent, she runs a separate flow. Different client ID, different scope set (code:read code:write), different consent screen, different refresh token.
The key idea: the scope Alice approves at this step is the ceiling, not the per-call scope. The refresh token she grants reporting-agent carries reports:read as its maximum. When the agent later calls the token exchange service (as described in the previous post), the exchange narrows the scope further based on the specific downstream service being called. Alice’s consent sets the upper bound; the token exchange sets the actual permission on each call.
This separation is important. Alice is not approving every individual API call. She is approving a bounded capability, and trusting the delegation chain to narrow things appropriately.
Incremental Consent for Evolving Agents
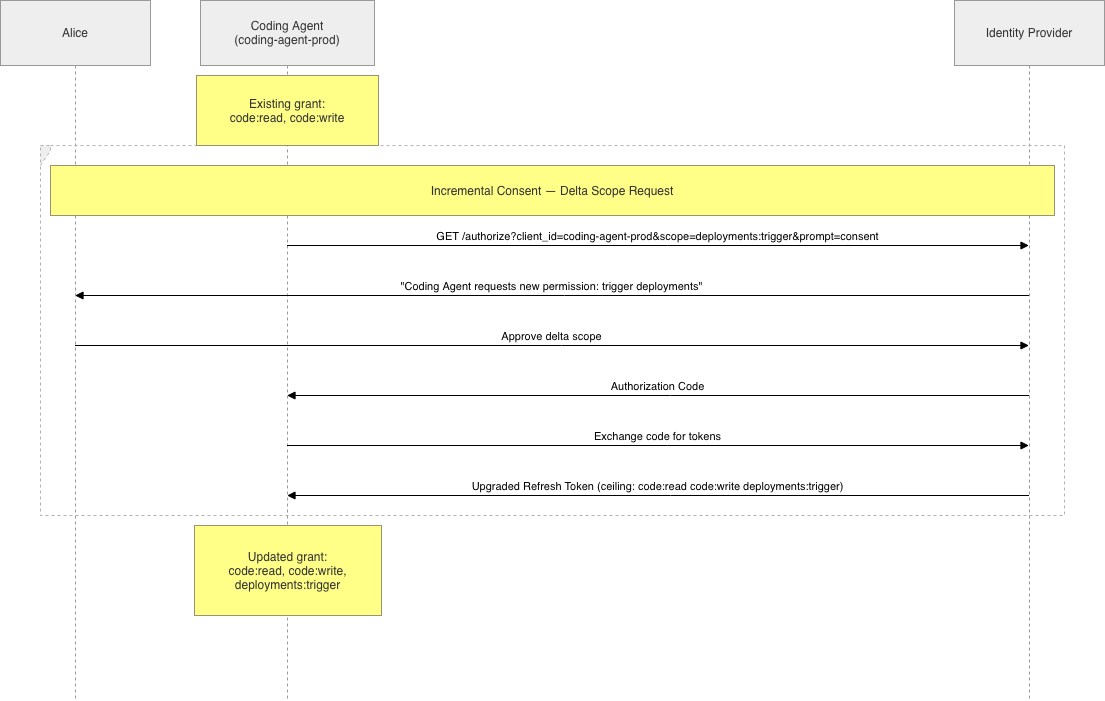
Agents change. Six weeks after Alice first approved coding-agent, the agent’s capabilities expand. It now needs deployments:trigger to push code through to staging. Alice’s existing refresh token has code:read code:write as its ceiling and cannot cover the new scope.
You have two options.
Prompt for the delta: The agent initiates a new authorization request that includes only the new scope. The consent screen shows Alice what is changing: “Coding Agent is requesting a new permission: trigger deployments.” She approves, and the refresh token is upgraded, or a second token is issued alongside the first.
GET /authorize
?response_type=code
&client_id=coding-agent-prod
&scope=deployments:trigger
&prompt=consent
&state=abc456
Force full re-consent: For sensitive scope escalations, anything that moves the agent from read to write or touches production systems, requiring a fresh grant from scratch makes the decision visible rather than incremental. The UX cost is real, but so is the risk of scope creep through small, easily-approved increments.
A defensible policy: Allow delta consent for same-tier scopes, force full re-consent when crossing a sensitivity boundary (read to write, non-prod to prod, internal to external data). Record the consent decisions with timestamps and scope deltas so you can reconstruct how an agent’s permissions evolved.
Standing Authorization vs. Task-Scoped Authorization
Consent comes in two shapes, and agentic platforms need both.
Standing authorization is the default most teams reach for. Think of it like setting up ACH autopay for your homeowners association (HOA) dues. You authorize the HOA once to pull a fixed amount from your bank account every month. The payments run on schedule without you approving each one. You set the ceiling (the monthly amount), and the HOA operates within it indefinitely until you revoke the mandate. That is exactly how standing authorization works for agents. Alice grants reporting-agent a refresh token valid for 90 days. The agent runs on a schedule, exchanges the refresh token for short-lived access tokens, and does its work without Alice being involved. This is the right model when the agent’s task is ongoing and the scope is stable.
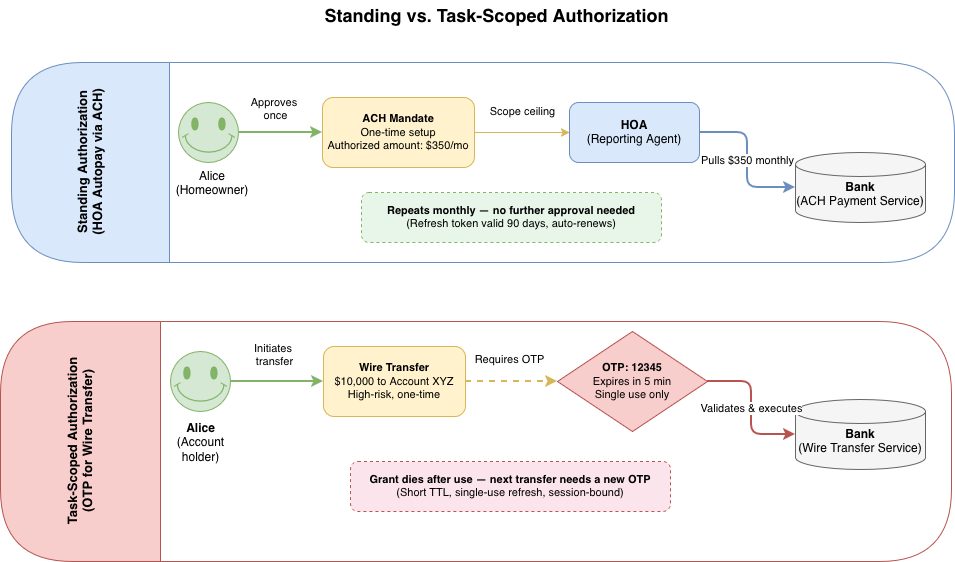
Task-scoped authorization is narrower. Think of the one-time password your bank sends to your phone when you initiate a wire transfer. The OTP is bound to that specific transaction, expires in minutes, and cannot be reused for a second transfer. You need a fresh code each time. That is task-scoped authorization. Alice is in a chat session with coding-agent and asks it to deploy a specific branch to staging. The agent requests a grant bound to this session and this task: short TTL, single-use refresh, tied to a session ID in the grant metadata. When the session ends, the grant is dead. This is the right model for high-risk, user-present actions where standing authority would be excessive.
The two compose. The coding-agent might hold a standing grant for code:read code:write and request task-scoped grants on top of it for sensitive operations like deployments:trigger. The standing grant handles the common case; the task-scoped grant handles the exception that needs a fresh “yes” from Alice.
Comparing the Two Client Models
| Dimension | Shared client for all agents | Per-agent client registration |
|---|---|---|
| Revocation granularity | All-or-nothing (affects every agent) | Per-agent (isolated blast radius) |
| Scope ceiling | Union of all agent needs (over-broad) | Tailored per agent (least-privilege) |
| Audit attribution | Shared client ID in every log | Distinct client ID per agent |
| Onboarding cost | Low (one-time setup) | Moderate (DCR automation required) |
| Compromise blast radius | Every agent that shares the client | One agent only |
Conclusion
The delegation pattern from the previous post is only as strong as the consent that seeds it. If every agent shares a client, the downstream token exchange has nothing meaningful to narrow from. If consent is granted once and never revisited, scope ceilings drift away from what Alice actually intended. If standing and task-scoped authorization are treated as the same thing, you end up over-authorizing routine work or under-authorizing sensitive actions.
Per-agent client registrations, explicit scope ceilings, incremental consent for evolving capabilities, and a clear line between standing and task-scoped grants give Alice real control and give your security team something defensible when someone asks how an agent came to hold the permissions it did.
There is a third case where agents running with no user present at all, like a scheduled agent that triggers at 2am. Standing authorization gets you partway there, but the model starts to strain when the human is fully out of the loop. Watch out for the next post in this series.